이 문제는 전형적인 bfs의 형태는 아니지만 자주 등장하는 형태입니다. 따라서 이러한 유형을 bfs로 푸는 것에 익숙해져야 합니다. 수빈이가 이동할 수 있는 곳인 (현재 위치 -1, 현재 위치 +1, 현재 위치 * 2)를 bfs의 형태로 탐색을 하여 해결합니다. 다만 주의해야 할 점은 리스트의 범위입니다. 이러한 문제의 경우 인덱스 에러가 쉽게 발생할 수 있으므로 범위에 신경을 써서 문제를 해결해주셔야 합니다. 소스코드는 다음과 같습니다.
이 문제는 단순한 BFS에서 아주 조금 응용을 하면 쉽게 해결할 수 있는 문제였습니다. 그래프를 입력받을 때 토마토가 들어있는 좌표를 따로 tomato라는 deque를 만들어 저장한다면 쉽게 해결할 수 있었습니다. 그 후로는 일반적인 bfs문제를 풀 때처럼 bfs를 적용합니다. 다만 전체 상자 안에 토마토가 익으려면 며칠이 걸리는지를 물어보는 문제였기 때문에 while 문 안에 for _ in range(len(tomato))를 두어서 이 해당하는 for문을 벗어날 때만 하나씩 count를 증가시켜주면 됩니다. for문을 추가해주는 이유는 한 번에 즉 하루에 bfs로 탐색할 수 있는 양이 tomato라는 deque에 추가되기 때문에 이 deque의 전체가 비면 하루가 지난 것 이기 때문입니다. 추가적으로 bfs로 탐색 후 전체 그래프에서 0 즉 익지 않은 토마토가 하나라도 존재하면 -1을 출력해 줍니다. 소스코드는 다음과 같습니다.
스택은 자료구조중에 하나로서 흔히 박스를 쌓는 구조로 설명을 한다. 이를 그림으로 표현하면 다음과 같다.
스택의 그림
위의 그림을 보면 2, 4, 6, 8, 10 의 순서로 삽입을 한 형태이다. 먼저 들어온 2가 바닥에 있고 나중에 넣은 10이 위에 있음을 알 수 있다. 이를 상자를 쌓았다고 가정해보자. 상자의 밑 부분 부터 뺄 수 없으므로 당연히 맨 위에 부분부터 뺄 수 있을 것이다. 스택 역시 마찬가지이며 10 부터 뺼 수 있음을 알 수 있다. 이를 후입선출이라 하며 영어로 LIFO(Last In First Out)이다. 그렇다면 스택의 ADT를 살펴보자. 다음과 같다.
void StackInit(Stack * pstack);
// 스택의 초기화를 진행한다.
// 스택 생성 후 제일 먼저 호출되어야 하는 함수이다.
int SIsEmpty(Stack * pstack);
// 스택이 빈 경우 TRUE(1)을, 그렇지 않은 경우 FALSE(0)을 반환한다.
void SPush(Stack * pstack, Data data);
// 스택에 데이터를 저장한다. 매개변수 data로 전달된 값을 저장한다.
Data SPop(Stack * pstack);
// 마지막에 저장된 요소를 삭제한다.
// 삭제된 데이터는 반환이 된다.
// 본 함수의 호출을 위해서는 데이터가 하나 이상 존재함이 보장되어야 한다.
Data SPeek(Stack * pstack);
// 마지막에 저장된 요소를 반환하되 삭제하지 않는다.
// 본 함수의 호출을 위해서는 데이터가 하나 이상 존재함이 보장되어야 한다.
이제 이 ADT를 기반으로 배열 기반, 연결 리스트 기반으로 구현해보자.
배열 기반 스택 구현
스택에서 구현해야 하는 함수는 push, pop이 있고 이를 top이라는 스택의 가장 윗 부분을 담당하는 변수를 이용하여 구현한다. 가장 중요한 함수는 push, pop으로 push의 경우 top을 한칸 올리고 top이 가리키는 위치에 데이터를 저장하고 pop의 경우 top이 가리키는 데이터를 반환하고, top을 아래로 한칸 내린다. push연산을 그림으로 표현하면 다음과 같다.
push 연산
확인할 수 있는 점은 top의 시작은 -1 이며 하나의 데이터가 들어올 때 0이 된다는 것이다. 처음에 A를 추가할 때 top이 하나 증가한 뒤 해당 top의 위치에 원소가 추가되는것을 확인할 수 있으며 이후로도 마찬가지 이다.
이 문제의 경우 알고리즘의 분류상 구현 문제로 문제에서 주어진 대로만 차분하게 구현하면 쉽게 해결할 수 있는 문제였습니다. 다만 실버 5 티어라는 난이도에 비해 정답률이 29%로 낮은 편인데 그 이유는 메모리 제한 때문이라 생각됩니다. 저 역시 pypy3로 풀었을 때 메모리 초과 판정을 받았고 pypy는 시간 복잡도가 좋은 대신 공간 복잡도 측면에서 불리하다는 사실을 알게 되어 python3으로 해결한 결과 정답 판정을 받을 수 있었습니다. 문제의 조건을 그대로 구현하면 되는 문제이기 때문에 해결방안은 따로 제시하지 않습니다.
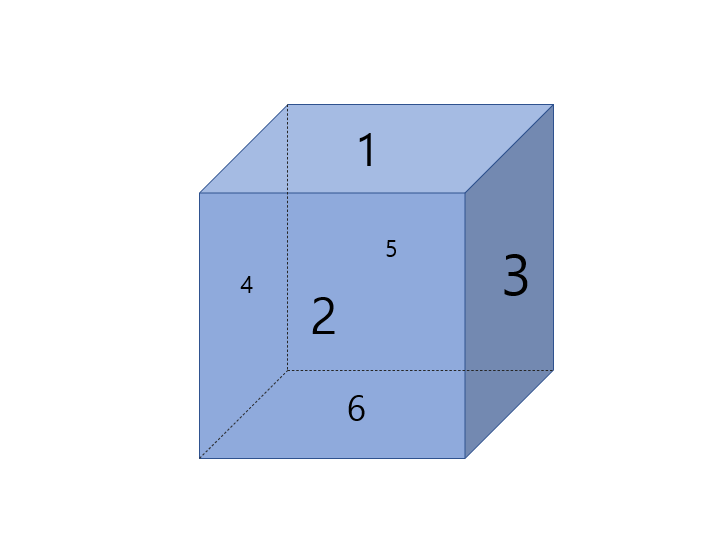
이 문제의 경우 골드 4 티어로 비교적 높은 난이도를 가지고 있지만 사실 구현으로 분류되는 문제의 특성상 차분하게 문제에서 제시한 조건을 따라가면 쉽게 해결할 수 있는 문제였습니다. 다만 주사위라는 공간지각 능력이 필요한 문제라서 조금 생각을 해야 합니다. 이 문제를 푸는 데 있어서 가장 중요한 것은 전개도입니다. 전개도 대로 주사위를 만들면 아래의 그림과 같습니다.
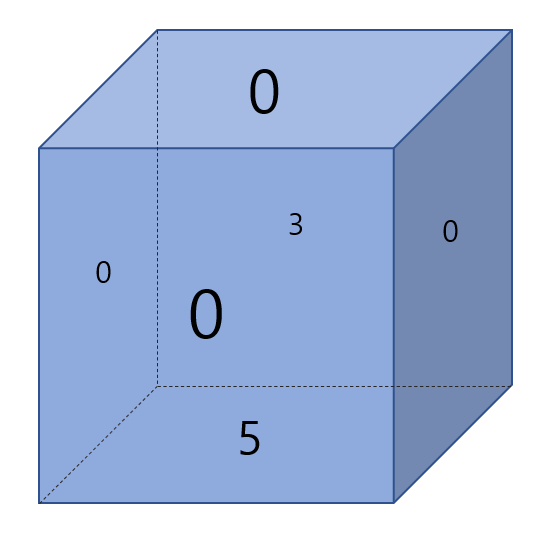
윗면 1 아랫면 6 앞면 2 뒷면 5 왼쪽면 4 오른쪽면 3
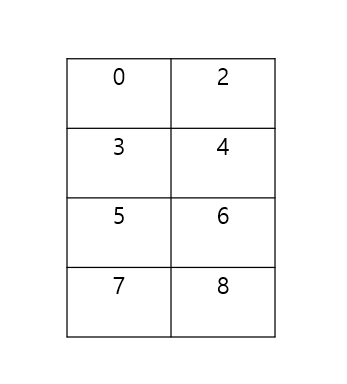
이를 동쪽, 서쪽, 남쪽, 북쪽으로 돌리더라도 주사위의 특성상 마주보는 면의 합은 7입니다. 위 주사위 그림의 면에 배정된 숫자는 문제에서 주어진 조건 "주사위는 지도 위에 윗 면이 1이고, 동쪽을 바라보는 방향이 3인 상태로 놓여져 있으며, 놓여 있는 곳의 좌표는 (x, y)이다. 가장 처음에 주사위에는 모든 면에 0이 적혀져 있다." 를 반영한 것입니다. 즉 위치를 저렇게 잡은 후 모든 주사위의 면을 0으로 초기화합니다. 그 후 문제에서 테스트 케이스로 주어진 지도에 0행 0열에 주사위를 배치합니다. 첫 번째 예시에서 맵은 다음과 같습니다.
과정 및 주사위 그림은 다음과 같습니다.
1. 시작지점에 위치(0행 0열)
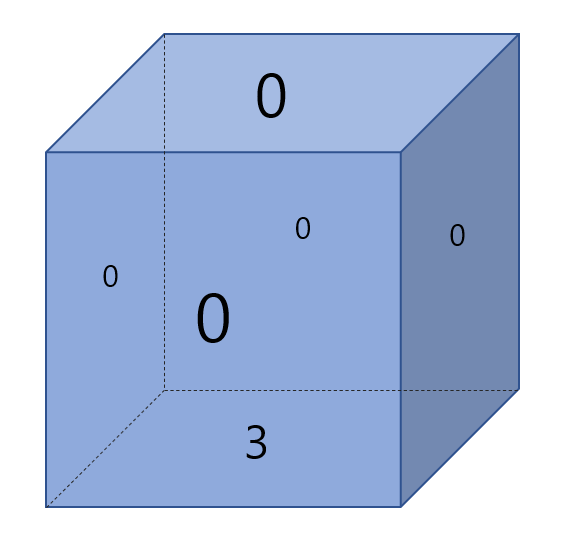
2. 명령이 4 이므로 남쪽으로 회전 1행 0열이 3 이므로 주사위의 밑면은 3, 윗면은 0이 됨 따라서 0 출력
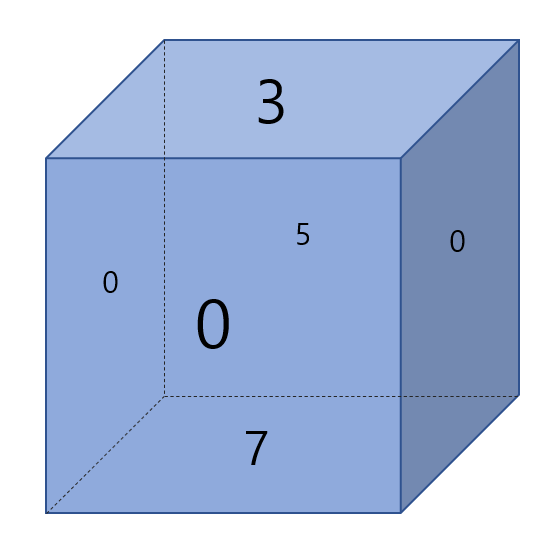
3. 명령이 4 이므로 남쪽으로 회전 2행 0열이 5 이므로 주사위의 밑면은 5, 뒷면은 3, 윗면은 0이 됨 따라서 0 출력
4. 명령이 4 이므로 남쪽으로 회전 3행 0열이 7 이므로 주사위의 밑면은 7 뒷면은 5 윗면은 3이 됨 따라서 3 출력
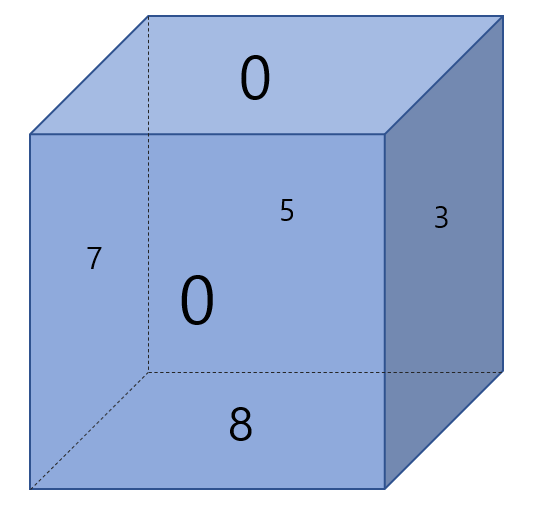
5. 명령이 1 이므로 동쪽으로 회전 3행 1열이 8 이므로 주사위의 밑면은 8 왼쪽면은 7 오른쪽면은 3 뒷면은 5 윗면은 0 따라서 0 출력
이러한 과정을 반복한다.
문제 해결을 위한 팁
처음의 주사위의 전개도를 2차원 리스트의 형태로 구현한 후 문제를 해결하려 하였으나 예상보다 복잡해지는 바람에 다른 방법을 찾던 중 단순하게 일차원 리스트로 해결할 수 있음을 알게 되었고 해결방법은 다음과 같다. 먼저 리스트를 다음과 같이 설정한다.
dice = [0, 0, 0, 0, 0, 0]
윗면 1 아랫면 6 앞면 2 뒷면 5 왼쪽면 4 오른쪽면 3
그 후 이 그림을 보면서 항상 리스트의 0번째가 윗면, 1번째가 앞면, 2번째가 오른쪽면 이런 식으로 5번째가 아래쪽면이라는 것을 고정한 뒤 swap을 해준다. 즉 남쪽으로 한번 회전을 해주면 위의 그림에서 왼쪽 오른쪽면은 그대로 있고 나머지 4면이 회전을 하는 형태이다. 따라서 이를 이렇게 표현할 수 있다.
이 문제의 경우 N이 100,000이기 때문에 이중 for문을 이용해서 풀게 되면 O(N^2) = 10,000,000,000 번의 연산을 최악의 경우 수행하게 됩니다. 따라서 이 문제의 경우 python3으로 이중 for문을 이용하면 제한시간 2초내에 풀 수 없습니다. (다만 pypy3로 제출하면 정답판정을 받게 되는데 데이터의 추가가 필요해 보입니다.) 따라서 이 문제는 O(N)으로 해결해야 하는 문제 입니다. 따라서 한번의 반복문으로 해결할 수 있는 방법을 찾아야 합니다.